Jetson Generative AI – Live LLaVA

Requirements
|
Hardware / Software
|
Notes
|
|---|---|
|
Jetson AGX Orin (64GB)
|
Recommended for best performance
|
|
Jetson AGX Orin (32GB)
|
Good performance for most use cases
|
|
Jetson Orin NX (16GB)
|
Solid performance
|
|
Jetson Orin Nano (8GB)
|
Minimum requirement – use smaller models
|
|
JetPack 6 (L4T r36.x)
|
Required for latest optimizations
|
|
USB camera or CSI camera
|
For live video input
|
|
NVMe SSD highly recommended
|
For storage speed and space
|
|
22GB for nano_llm container
|
Container image storage
|
|
>10GB for models
|
Vision-language model storage
|
Supported Models
Supported Models
The following vision-language models are optimized for Live LLaVA:
`liuhaotian/llava-v1.5-7b`,`liuhaotian/llava-v1.5-13b``liuhaotian/llava-v1.6-vicuna-7b``liuhaotian/llava-v1.6-vicuna-13b`
`Efficient-Large-Model/VILA-2.7b``Efficient-Large-Model/VILA-7b``Efficient-Large-Model/VILA-13b``Efficient-Large-Model/VILA1.5-3b``Efficient-Large-Model/Llama-3-VILA1.5-8B``Efficient-Large-Model/VILA1.5-13b`
VILA-2.7bVILA1.5-3bVILA-7bLlava-7bObsidian-3B
Step-by-Step Setup
Step-by-Step Setup
1. Verify Camera Connection
1. Verify Camera Connection
Check that your camera is properly connected and detected:
2. Clone and setup jetson-containers
3. Launch Live LLaVA
3. Launch Live LLaVA
Start the VideoQuery agent with your camera:
4. Access the Web Interface
https://<jetson-ip>:8050
5. Configure Prompts
In the web interface, you can:
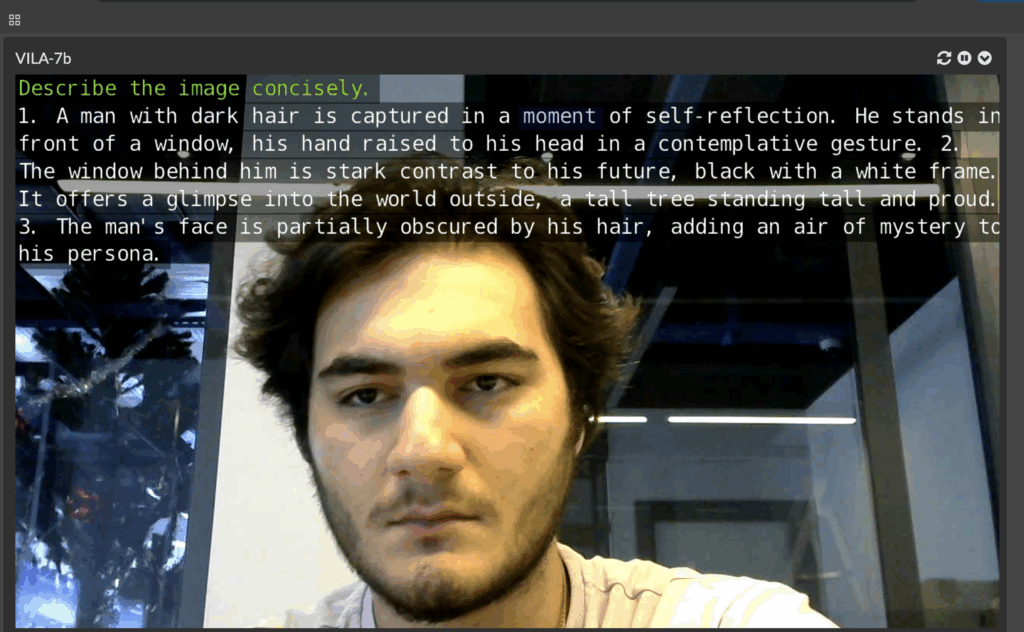
Live LLaVA Face Detection
Real-time Object Detection
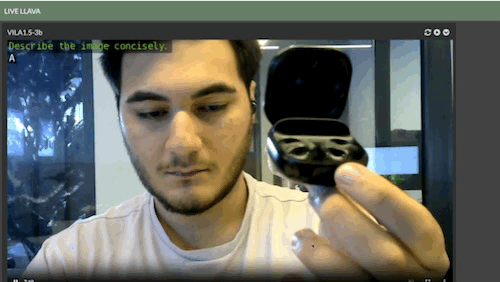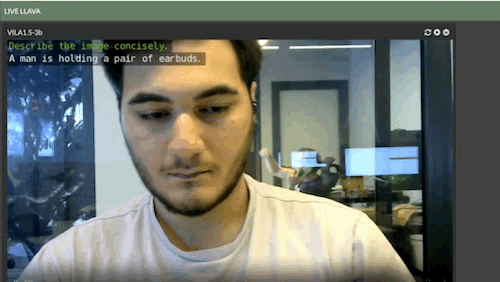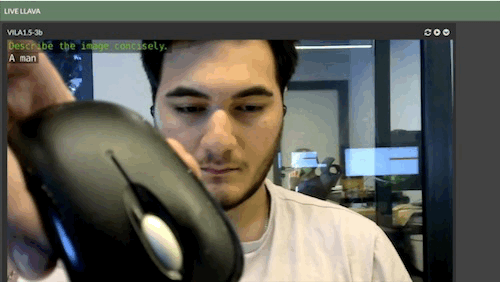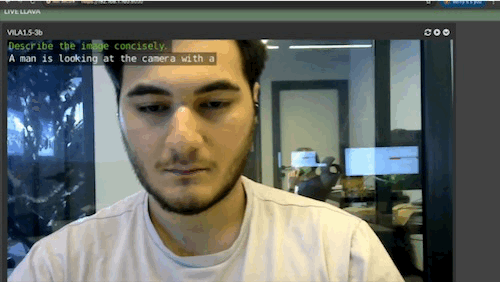
Live LLaVA Object Detection
Custom Prompting
Custom Prompting
You can customize the analysis with specific prompts:
Pre-recorded Video Analysis
Supported Formats
MP4, MKV, AVI, FLV (with H.264/H.265 encoding)Live network streams (RTP, RTSP, WebRTC)USB/CSI cameras
Video files (MP4, AVI, etc.)Network streams (WebRTC, RTSP)Display output
NanoDB Integration
Enable reverse-image search and database tagging by integrating with NanoDB:
This enables:
Video VILA – Multi-frame Analysis
Video VILA – Multi-frame Analysis
Troubleshooting
How to fix freezing issues while loading the model?
The documentation uses the old awq4; instead, use the --quantization q4f16_1 parameter.
The 13B model eventually freezes on the Jetson AGX Orin 32GB due to running out of tokens; if speed is needed, we recommend using VILA-7B or VILA-2.7B instead.
How to fix the issue of the camera not being detected
To make a USB camera accessible inside the container, add the parameter --device /dev/video0 when running the container. This maps the host’s camera device into the container, allowing applications inside to access the video stream as if it were running natively on the host system.
How to Avoid Color Distortion Issues with Logitech C505e Using MJPEG Codec ?
To prevent color distortion problems on the Logitech C505e camera, we recommend using the --video-input-codec mjpeg parameter. This forces the camera to use the MJPEG codec, which is better supported and helps maintain accurate color reproduction.
Resolution Limitation
For stable FPS performance, use the parameters --video-input-width 1280 and --video-input-height 720. These settings limit the video resolution to 1280×720, helping maintain smoother and more consistent frame rates.
|
Issue
|
Fix
|
|---|---|
|
Camera not detected
|
Check USB connection, verify with `ls /dev/video*`
|
|
WebRTC not working
|
Use Chrome, disable WebRTC local IP hiding flag
|
|
Out of memory errors
|
Use smaller model (VILA1.5-3b), reduce context length
|
|
Low frame rate
|
Reduce max-new-tokens, use smaller model, check camera resolution
|
|
Video codec errors
|
Verify input format is H.264/H.265, check jetson_utils installation
|
For more information about Live LLaVA and advanced configurations, visit the NanoLLM GitHub repository.