Jetson Generative AI – LlamaSpeak

Vision wasn’t the only modality transformed by Transformers—**LlamaSpeak** brings the power of large language models to spoken conversations, streaming speech-to-text (ASR), intelligent response generation, and text-to-speech (TTS) back out in real time on your Jetson device.
In this article you’ll learn how to run NanoLLM’s WebChat agent (nicknamed LlamaSpeak) on Jetson using NVIDIA TensorRT/MLC and Riva Speech Skills.
Requirements
|
Hardware / Software
|
Notes
|
|---|---|
|
Jetson AI Kit / Dev Kit
|
Orin AGX / Orin NX recommended for best latency
|
|
JetPack 6 (L4T r36.x)
|
Needed for latest pre-built containers
|
|
USB microphone & speakers / headset
|
Confirm with `arecord -l`
|
|
Riva Speech Skills 2.15+
|
Provides low-latency ASR engine
|
|
Hugging Face token
|
Needed for gated Meta-Llama weights
|
Obtaining Your Hugging Face Token
To download the gated Llama checkpoints you’ll need a personal access token (PAT) from Hugging Face:
Step-by-Step Setup
1. Clone the repository
2. Enter the repo
3. Update APT & install pip3
4. Install helper Python packages
5. Verify audio devices
If your microphone doesn’t appear, check USB connections and reboot.
6. Start the Riva server
Accept the license prompt and wait until the log shows State = READY.
7. Launch LlamaSpeak
The first run downloads the model (~ 9 GB for 8-bit, ~4 GB for 4-bit) and container layers.
8. Open the Web UI
WebChat serving at https://0.0.0.0:8050
https://<jetson-ip>:8050
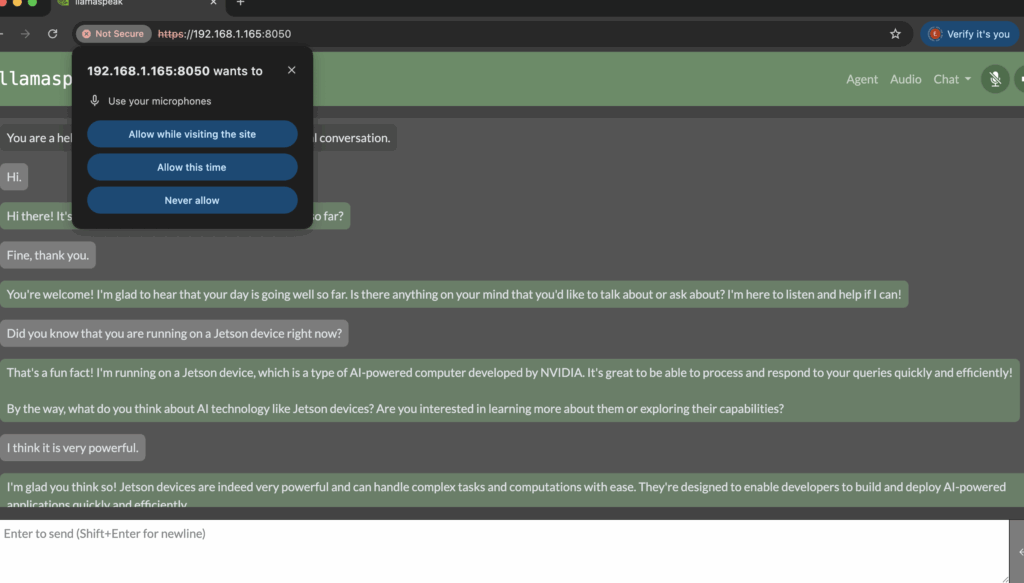
LLM Chat Interface
9. Talk to your Jetson
10. (Advanced) Enable multimodality
Launch it with a VLM and drag an image to the chat:
See the NanoVLM docs for more supported checkpoints.
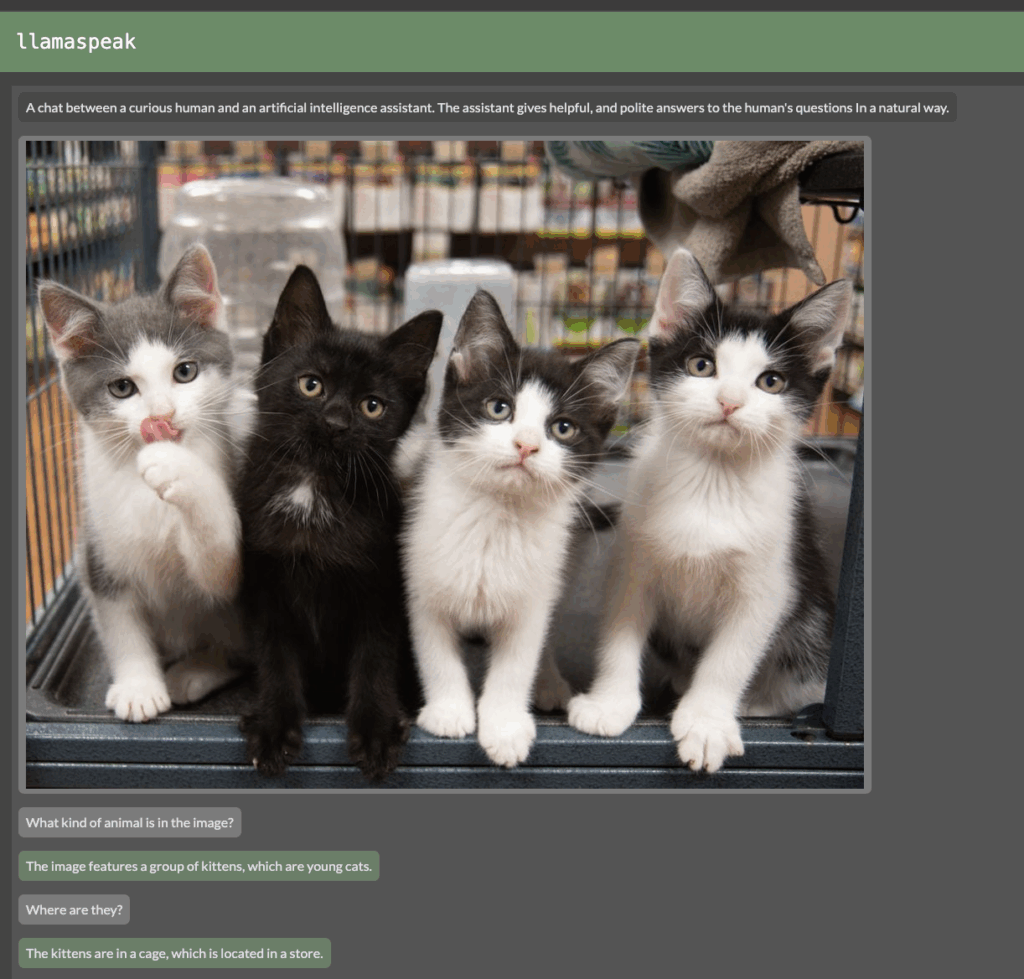
Multimodal Chat Interface
LlamaSpeak in Action
LlamaSpeak in Action
Text-Only LLM Chat
Text-Only LLM Chat
LLM Demo Video:
LLM Demo Video:
Multimodal Vision Chat
Multimodal Vision Chat
Multimodal Demo Video:
Multimodal Demo Video:
Troubleshooting
How to resolve the NGC Registry access 401 Unauthorized error?
After signing up and logging in to the NGC Catalog website, an API key must be generated from the “Setup” section. Then, run the command docker login nvcr.io in the terminal. In the login prompt, enter $oauthtoken as the username and the generated API key as the password. If the message “Login Succeeded” appears, the process has been successfully completed.
“model-repo” Error When Running Riva Manually Without riva_start.sh
riva_start.shThe tutorial only invokes riva_start.sh, which handles model repository setup internally. However, when running Riva manually using docker run, we encountered a "model-repo" error due to missing model repository configuration.
To resolve this, we explicitly defined the model path using both an environment variable and a bind mount:
By setting the RIVA_MODEL_REPO environment variable and bind-mounting the local models directory to the container path /data/models, the error was resolved successfully.
How to Prevent Port Conflicts (“port is already in use” Error)
The default port (e.g., 8050) may already be occupied by another service, leading to a “port is already in use” error. To prevent this, specify custom ports when launching Riva by using flags like --web-port 8443 and --ws-port 9443. This ensures Riva runs without interfering with other applications.
How to Resolve the Microphone Not Detected Issue
When connecting via HTTPS through the browser, sometimes the browser may not automatically prompt for microphone or speaker access permissions. In such cases, the user manually bypasses the security warning by selecting “Advanced” > “Proceed.” After the page loads, microphone and speaker permissions are granted manually by clicking the padlock icon in the address bar.
How to Fix the Riva Logs Getting Stuck in an Infinite “Waiting” Loop
If the Riva logs show an endless “waiting” loop, follow these steps:
-
Wait until the status changes to READY before proceeding.
-
If the loop persists, it may indicate insufficient VRAM. In that case, try selecting a smaller model to reduce memory requirements.
This approach helps resolve the “waiting” hang and ensures Riva initializes properly.
|
Issue
|
Fix
|
|---|---|
|
Mic not detected
|
Use a powered USB sound card; reconfirm with `arecord -l`
|
|
Stuck on Waiting for Riva
|
Ensure the Riva container is running and ports are exposed
|
|
Out-of-memory errors
|
Use a 4-bit quantized checkpoint or a 7-B model (e.g., Mistral-7B)
|
For more information about NanoLLM and advanced configurations, visit the NanoLLM GitHub repository.