Jetson Generative AI – Whisper

Automatic Speech Recognition reaches new levels of accuracy and reliability with OpenAI’s Whisper—a pre-trained model that transforms spoken words into text with remarkable precision in real time on your Jetson device.
In this article you’ll learn how to run Whisper on Jetson using optimized containers, featuring Jupyter Lab integration for interactive speech recognition experiments and real-time audio transcription capabilities.
Requirements
|
Hardware / Software
|
Notes
|
|---|---|
|
Jetson AGX Orin (64GB)
|
Recommended for best performance
|
|
Jetson AGX Orin (32GB)
|
Good performance for most use cases
|
|
Jetson AGX Orin (16GB)
|
Solid performance
|
|
Jetson AGX Orin (8GB)
|
Basic functionality
|
|
JetPack 5 (L4T r35.x) or JetPack 6 (L4T r36.x)
|
Both versions supported
|
|
NVMe SSD highly recommended
|
For storage speed and space
|
|
6.1GB for whisper container
|
Container image storage
|
|
Microphone access
|
For live audio recording
|
|
HTTPS browser support
|
Required for microphone access in Jupyter
|
Note: Whisper supports multiple languages and can handle various audio qualities, making it ideal for diverse speech recognition applications.
Step-by-Step Setup
1. Clone jetson-containers repository
2. Install jetson-containers
3. Launch Whisper container
The container has a default run command that automatically starts the Jupyter Lab server with SSL enabled.
4. Access Jupyter Lab interface
https://:8888
5. Handle SSL certificate warning
You will see a security warning message in your browser:
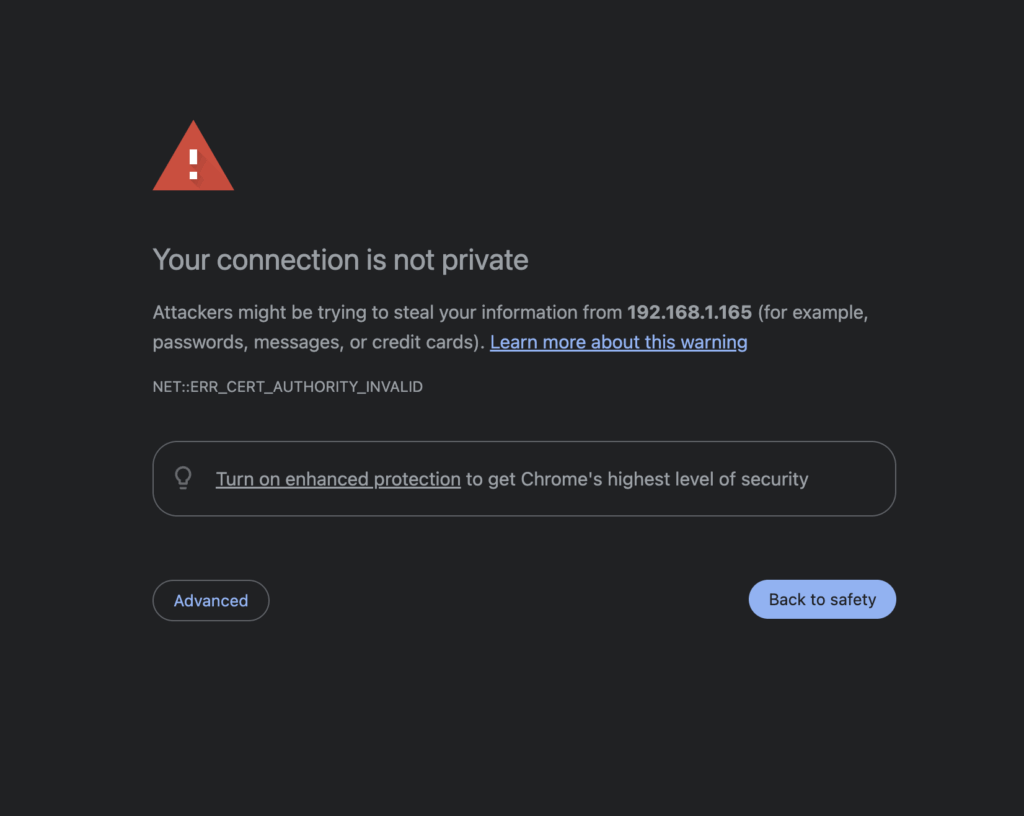
Browser SSL certificate warning for Jupyter Lab
- Press “Advanced” button
- Click “Proceed to (unsafe)” link to access the Jupyter Lab interface
6. Login to Jupyter Lab
Default password:`nvidia`
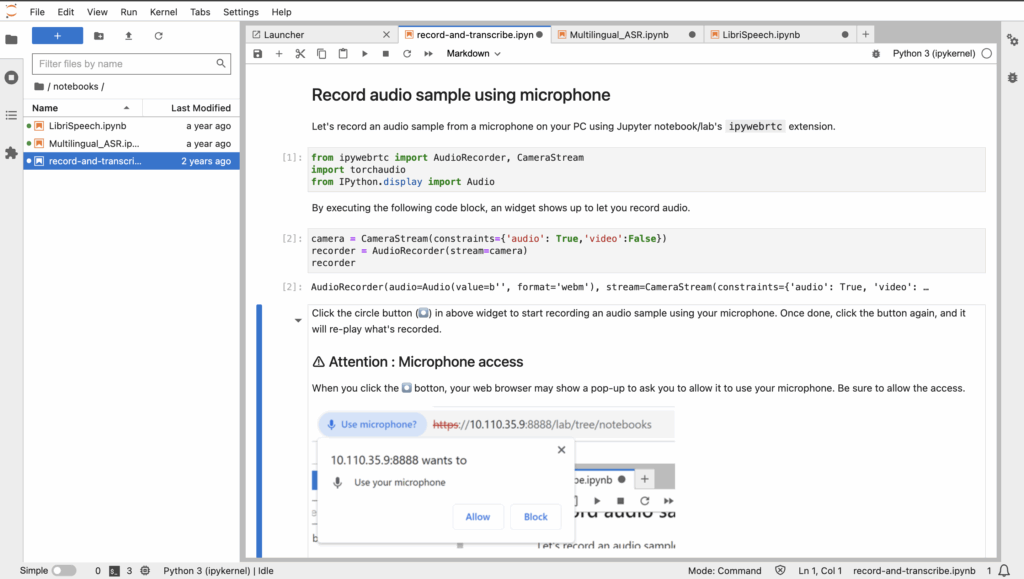
Jupyter Lab Login
Available Notebooks
- Standard Whisper demos – Basic transcription examples
- record-and-transcribe.ipynb – Interactive recording and transcription (added by jetson-containers)
- Record audio samples using your PC’s microphone
- Apply Whisper’s medium model for transcription
- See real-time results in the notebook interface
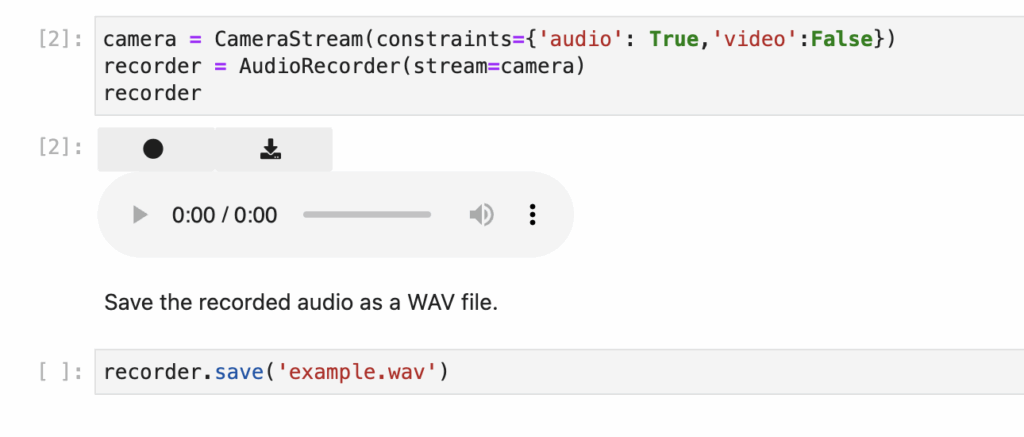
Recording Interface
Whisper in Action
Interactive Recording and Transcription
Watch the complete process of using Whisper on Jetson – from launching Jupyter Lab, recording audio with the browser microphone, to seeing the transcription results in real-time.
Whisper Jupyter Notebook Demo:
Custom Audio Files
You can also transcribe pre-recorded audio files:
Batch Processing
Process multiple audio files efficiently:
Language Detection
Troubleshooting
|
Issue
|
Fix |
|---|---|
|
Browser blocks microphone
|
Use HTTPS, allow microphone permissions in browser settings
|
|
SSL certificate warning
|
Click “Advanced” → “Proceed to unsafe” to continue
|
|
Container fails to start
|
Ensure jetson-containers is properly installed
|
|
Out of memory errors
|
Use smaller Whisper model (tiny, base instead of medium/large)
|
|
Audio not recording
|
Check microphone connection, verify browser permissions
|
|
Slow transcription
|
Use smaller model, ensure sufficient GPU memory available
|
For more information about Whisper and advanced configurations, visit the OpenAI Whisper GitHub repository and jetson-containers documentation.